SQL
Note
These notes are mostly written with MySQL in mind.
Important
The order of keywords matters! The keywords below are listed in the order they should be used.
General
- Comments start with
-- TRUEandFALSEare the same as1and0respectively- In MySQL, single and double quotes are the same except for escaping (same as JavaScript, Python, etc)
- in Postgres, use single quotes for strings
- Table/column names that are also keywords (ex.
trigger) must be quoted using `
Variables
- must start with
@ - can only hold simple data types: integer, decimal, float, string, NULL
SET @start_date = '2023-01-01'; -- semicolon is important
SELECT *
FROM users
WHERE created_at > @start_date
Dates & Times
Important
Make sure to put dates in quotes! Without quotes, 2022-12-25 will be interpreted as "the number 2,022 minus 12 minus 25"
- Use
NOW()to get the current timestamp - To cast to a timestamp:
TIMESTAMP(): date and timeDATE(): date without timeTIME(): time only
# created_at is a timestamp, which looks like '2022-12-01 14:27:08'
WHERE DATE(created_at) <= '2022-12-25'
# or
WHERE TIME(created_at) > '12:00:00'
- If the column has an index, you can increase the end date by 1 to avoid casting and improve performance. For example, to select all records created on 2022-12-25:
WHERE
created_at >= '2022-12-25'
AND
created_at < '2022-12-26'
INTERVAL
- Select dates in the last 24 hours
- interval names are singular, ex.
DAY,WEEK,MONTH
- interval names are singular, ex.
WHERE created_date >= NOW() - INTERVAL '1 DAY'
Arrays (Postgres)
- write array values as literals using
'{}'orARRAY[]
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
-- or
INSERT INTO sal_emp
VALUES ('Bill',
ARRAY[10000, 10000, 10000, 10000],
ARRAY[['meeting', 'lunch'], ['training', 'presentation']]);
SELECT pay_by_quarter[3] FROM sal_emp;
-- if using slices, use them for all dimensions
SELECT schedule[1:2][1:1] FROM sal_emp WHERE name = 'Bill';
UPDATE sal_emp SET pay_by_quarter[1:2] = '{27000,27000}'
WHERE name = 'Carol';
||can concatenate arrays, or add elements to an array
ARRAY[1, 2] || ARRAY[3, 4] -> {1, 2, 3, 4}
ARRAY[1, 2, 3] || 4 -> {1, 2, 3, 4}
0 || ARRAY[1, 2, 3] -> {0, 1, 2, 3}
- to check if an array contains an element, use
ANY ()
WHERE 10000 = ANY (pay_by_quarter)
Keywords
SELECT / AS / FROM
SELECT
id,
name,
owner_name AS owner
FROM pets
- Concatenate strings:
SELECT
first_name || ' ' || last_name AS full_name
SELECT DISTINCT
SELECT DISTINCT owner_name
FROM pets
- Select all distinct combinations of
nameandowner_name
SELECT DISTINCT name, owner_name
FROM pets
Count rows
SELECT COUNT(*)
FROM pets
WHERE species = 'cat'
- Also see [[#Count number of distinct values]] and [[#GROUP BY]]
CASE
- Like switch statements (no fallthrough)
SELECT
a.name,
CASE
WHEN a.rating <= 2 THEN 'Bad'
WHEN a.rating = 3 THEN 'Average'
WHEN a.rating >= 4 THEN 'Good'
END AS quality
FROM
albums a
UPDATE
albums a
SET
a.album_type = CASE
WHEN a.track_count = 1 THEN 'Single'
WHEN a.track_count <= 5 THEN 'EP'
# fallback to existing value, otherwise it will be set to NULL
ELSE a.album_type
END
INSERT
INSERT INTO pets (name, species, age, owner_id)
VALUES ('Rover', 'dog', 3, 1)
- to insert multiple rows, add multiple sets of values
INSERT INTO pets (name, species, age, owner_id)
VALUES ('Rover', 'dog', 3, 1), ('Spot', 'dog', 1, 1)
INSERT IGNORE
- ignores errors and moves on to the next
INSERT
INSERT INTO pets (id, name) VALUES (1, 'Rover')
INSERT INTO pets (id, name) VALUES (1, 'Spot') # errors
INSERT IGNORE INTO pets (id, name) VALUES (1, 'Spot') # doesn't error, does nothing
REPLACE (upsert)
- inserts the row if it doesn't exist, deletes it and inserts a replacement if it does
REPLACE INTO pets (id, name) VALUES (1, 'Rover') # inserts (if the database is empty)
REPLACE INTO pets (id, name) VALUES (1, 'Spot')
Conditional inserts
- only inserts the row if this owner does not already have a dog
- note the use of
SELECTinstead ofVALUES
- note the use of
INSERT INTO pets (name, species, age, owner_id)
SELECT 'Rover', 'dog', 3, 1
WHERE NOT EXISTS (SELECT * FROM pets WHERE species = 'dog' AND owner_id = 1)
UPDATE / SET
Warning
Don't forget the WHERE clause - otherwise you'll update every row in the table!
UPDATE
pets p
SET
p.sound = 'meow',
p.fluffy = 1
WHERE
p.species = 'cat'
Update based on records from another table
UPDATE
pets p
SET
p.owner_name = u.name
FROM
users as u
WHERE
p.owner_id = u.id
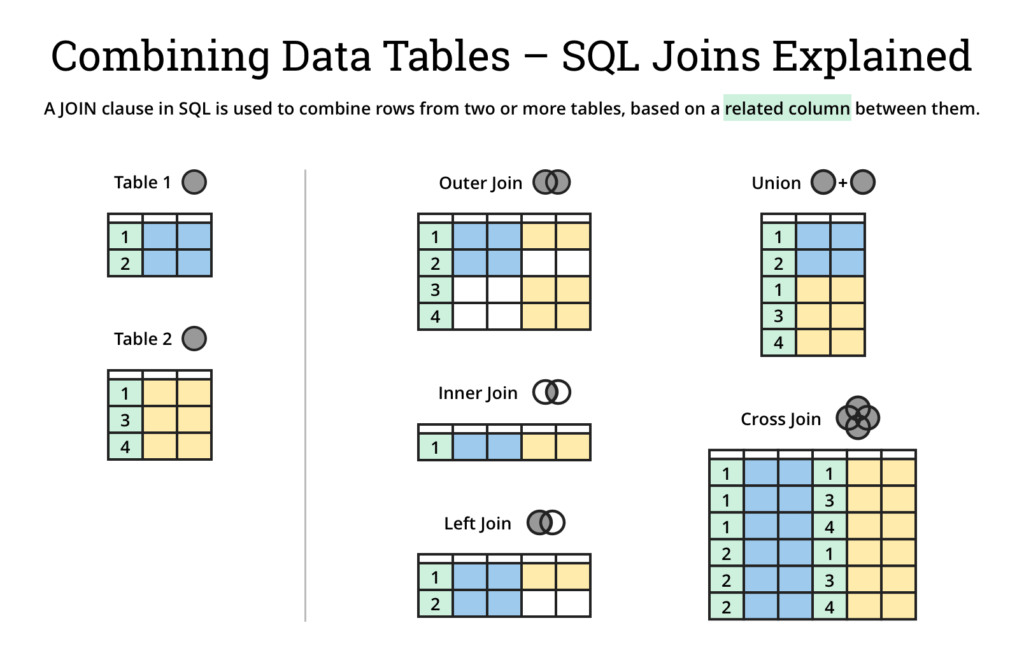
JOIN
SELECT
u.id,
u.name,
p.name AS petName,
p.species
FROM
database.users u
JOIN database.pets p ON p.owner_id = u.id
- INNER JOIN (default): returns only rows where the value matches in both tables
- LEFT JOIN: returns all rows from first table, and matching rows from second table
- RIGHT JOIN: returns all rows from second table, and matching rows from first table
- OUTER JOIN/FULL JOIN: returns all rows from both tables, like a combination of LEFT JOIN and RIGHT JOIN
- rows without matching values in the other table get
NULL(white squares in the example below)
- rows without matching values in the other table get
- CROSS JOIN: returns every possible combination of rows
- doesn't require an
ONclause
- doesn't require an
USING
USING (user_id)is a shortcut forON A.user_id = B.user_id- with
USING, the join column only appears once in the result, so you don't need to qualify it withTABLE_NAME.column_name
- with
SELECT users.id, pets.id, address
FROM users
JOIN pets USING (address)
Select rows that don't have a match in the other table
- this will select all users who don't have pets
- [[#Select rows that don't meet a condition in another table]] is equivalent, test both for performance
SELECT
*
FROM
database.users u
LEFT JOIN database.pets p ON p.owner_id = u.id
WHERE p.owner_id IS NULL
WHERE
SELECT *
FROM pets
WHERE
species = 'cat'
OR species = 'dog'
AND age >= 1
Boolean and null checking
- Use
ISandIS NOTwhen comparing againstTRUE,FALSE, orNULL
SELECT *
FROM pets
WHERE
first_name IS NOT NULL
AND last_name IS NULL
Check if a match exists
- This will return an empty record if there is no match, or
1if there is a match. This avoids pulling the whole record if you just want to know if it exists.
SELECT 1
FROM pets
WHERE p.species = 'cat'
LIMIT 1
LIKE (pattern matching)
WHERE name LIKE '%alice%'
- Case sensitive:
WHERE name LIKE BINARY '%Alice%'
REGEXP_LIKE (regular expressions)
- Backslashes must be escaped
WHERE REGEXP_LIKE(name, '\\w+_\\d{4}_\\d{2}_\\d{2}')
IN (list of values)
Warning
The order of the returned rows doesn't necessarily match the order of the given values!
WHERE name IN ('Alice', 'Bob')
BETWEEN (ranges)
- Both sides are inclusive
- Also
NOT BETWEEN
WHERE id BETWEEN 100 AND 200
EXISTS and NOT EXISTS
- Lets you filter based on the results of another query
WHERE EXISTS ( ... )
AND EXISTS ( ... )
AND NOT EXISTS ( ... )
Select rows that share a value with other rows
- This will select pets that share an owner with at least one other pet
SELECT a.*
FROM pets a
WHERE EXISTS (
SELECT 1
FROM pets b
WHERE a.owner_id = b.owner_id
AND a.id <> b.id
)
Select rows that don't meet a condition in another table
- Select all users who do not own a cat
- [[#Select rows that don't have a match in the other table]] is equivalent, test both for performance
SELECT *
FROM users u
WHERE NOT EXISTS (
SELECT 1
FROM pets p
WHERE u.id = p.owner_id
AND p.species = 'cat'
)
HAVING
- WHERE cannot be used with aggregate functions, use HAVING instead
List all values that match more than one row
SELECT first_name, COUNT(*)
FROM users
GROUP BY first_name
HAVING COUNT(*) > 1
GROUP BY
- Often used in queries with aggregate functions to analyze each group of rows
- Count the number of rows matching each distinct value of a column (in the example, the number of pets belonging to each
owner_id):
SELECT owner_id, COUNT(*)
FROM pets
GROUP BY owner_id
GROUP BY and ordering
- By default, which row is returned from GROUP BY is not deterministic, so the following will not work as expected (returning the oldest pet for each owner)
SELECT owner_id, name, age
FROM pets
GROUP BY owner_id
ORDER BY age DESC
- To fix this, use an aggregate function
SELECT owner_id, name, MAX(age)
FROM pets
GROUP BY owner_id
ORDER BY age DESC
- You can only select columns that are used in the GROUP BY clause, or in an aggregate function as shown above
# this won't work since species isn't in the GROUP BY or an aggregate
SELECT
species, owner_id
FROM
pets
GROUP BY
owner_id
ORDER BY
SELECT id, name
FROM pets
ORDER BY id DESC -- or ASC
LIMIT / OFFSET
SELECT id
FROM pets
LIMIT 5
OFFSET 10
WITH / AS (subqueries/CTEs)
- Let you store temporary results (Common Table Expressions or CTEs) that you can refer to later
- MySQL does not let you combine UPDATE and [[#LIMIT / OFFSET]], this can be used to get around that
WITH ids AS (
SELECT
a.id
FROM
albums a
WHERE
a.stars = 5
LIMIT 10
)
UPDATE
albums a
SET
a.recommended = 1
WHERE
a.id IN (SELECT * FROM ids)
- To use multiple AS blocks:
WITH foo AS (
...
), bar AS (
...
)
- To select from multiple CTEs:
SELECT
foo.id AS foo, bar.id AS bar
FROM
foo
JOIN bar USING (id)
- You can also inline a subquery into a SELECT, but you still need to give it a name
SELECT
id
FROM (
SELECT
a.*
FROM
albums a
WHERE
a.stars = 5
) from five_star_albums
Functions
Warning
Do not put a space between the function name and parentheses!
Aggregate functions (COUNT, MAX, MIN, SUM, AVG)
COUNT(), MAX(), MIN(), SUM(), AVG()
Select based on an aggregate
- Select the youngest dog
- the
GROUP BYis important!
- the
SELECT
MIN(birth_date) as birth_date,
id
FROM
pets
WHERE
species = "dog"
GROUP BY
species
Count number of distinct values
SELECT COUNT(DISTINCT first_name) ...
Count rows with each distinct value
See [[#GROUP BY]]
CAST
| Format | Notes/Example |
|---|---|
| DATE | YYYY-MM-DD |
| DATETIME | YYYY-MM-DD HH:MM:SS |
| DECIMAL | takes two parameters (M, D) for max integer digits & number of decimal digits |
| TIME | HH:MM:SS |
| CHAR | fixed length string |
| NCHAR | string with the national character set |
| SIGNED | signed 64-bit int |
| UNSIGNED | unsigned 64-bit int |
| BINARY | binary string |
LENGTH (string length)
SELECT *
FROM pets
WHERE length(first_name) <= 5
JSON
MySQL
JSON_OBJECT
- Create a JSON object from key-value pairs
SET u.metadata = JSON_OBJECT('is_enrolled', TRUE, 'is_mobile', FALSE)
JSON_KEYS
- Get a JSON array from the keys of a JSON object
- see MEMBER_OF to use it in a WHERE or JOIN
SELECT JSON_KEYS(user.metadata)
JSON_CONTAINS_PATH
- Find out if a value exists at a path
- can provide many paths - second argument is "one" or "all", to check whether any or all of the paths have a value
WHERE JSON_CONTAINS_PATH(p.metadata, 'one', '$.processed_date')
WHERE JSON_CONTAINS_PATH(p.metadata, 'all', '$.created_date', '$.processed_date')
MEMBER_OF (in JSON array)
WHERE id MEMBER OF ('[1, 2, 3]')
- since JSON object keys are always strings, if you used cast the value being checked to a string
-- if `user.relationships` was a JSON field with something like '{ 123: 'sibling' }'
WHERE CONVERT(user.id, CHAR) MEMBER OF (JSON_KEYS(user.relationships))
JSON_EXTRACT
- Select based on values within JSON fields
- make sure to use backticks or nothing around the column name, not single or double quotes
- Returns NULL if the path is NULL
SELECT JSON_EXTRACT(column_name, '$.version') ...
- You can also use the
->operator
SELECT column_name->"$.version"
- To handle dates or datetimes:
DATE(JSON_UNQUOTE(JSON_EXTRACT(p.metadata, '$.created_date')))
CAST(JSON_UNQUOTE(JSON_EXTRACT(p.metadata, '$.created_date')) as datetime)
JSON_SET, JSON_INSERT, JSON_REPLACE
JSON_SET: Insert or update JSON dataJSON_REPLACE: same but only replaces existing valuesJSON_INSERT: same but only inserts new values- doesn't work if the object at the given path is NULL - use a CASE to check for this
UPDATE
users u
SET
u.metadata = CASE WHEN u.metadata IS NULL
THEN JSON_OBJECT('is_enrolled', TRUE)
ELSE JSON_SET(u.metadata, '$.is_enrolled', TRUE)
END
WHERE
u.id = 12345
JSON_REMOVE
- Remove the specified JSON key
UPDATE
users u
SET
u.metadata = JSON_REMOVE(u.metadata, '$.is_enrolled')
END
WHERE
u.id = 12345
See also
Postgres
[JSON functions (Postgres 13)](PostgreSQL: Documentation: 13: 9.16. JSON Functions and Operators)
- search inside JSON values with the
@>operator- or
@<to go the other way - JSON strings must be placed in double quotes (inside the single quotes)
- or
- use
NOTto negate - ex.NOT ids @> '"abc"'
-- ids = ["abc", "def"]
WHERE ids @> '"abc"'
-- user = { "name": "Bob", "age": 30 }
WHERE user @> '{"name": "Bob"}'
Tables
Create table
CREATE TABLE pets (
id int NOT NULL AUTO_INCREMENT,
owner_id int NOT NULL,
name varchar(255),
FOREIGN KEY (owner_id) REFERENCES Users(id),
PRIMARY KEY (id)
);
Drop (delete) table
- remove
IF EXISTSto error if the table doesn't exist - in Postgres you can add
CASCADEafter the table name(s) to also drop objects that depend on the table
DROP TABLE IF EXISTS fruit, vegetables;
Transactions
- Running scripts in a transaction lets you test & roll back changes
START TRANSACTION;
-- destructive code goes here - don't forget a semicolon at the end
;
-- add a SELECT here to verify that the changes look good
;
ROLLBACK;
-- or to commit the changes use COMMIT;
Configuration
DESCRIBE
- Prints a table's schema
DESCRIBE database.users
Auto increment
ALTER TABLE 'users' AUTO_INCREMENT = 1;
SQL mode
Get
SELECT @@GLOBAL.sql_mode;
Set
SET GLOBAL sql_mode = 'NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
Time zone
Get
SELECT @@global.time_zone;
SYSTEMmeans the timezone is set in themy.cnffile. To get the time zone offset:
SELECT TIMEDIFF(NOW(), UTC_TIMESTAMP);
Set
SET @@global.time_zone = '+00:00';
Renaming columns
Renaming existing columns can cause deployed code to break. One approach to safely renaming columns:
- update the code to handle both the old and new names and deploy
- rename the column
- update the code to remove the old name
Another approach:
- add a new column with the new name and copy the data over
- update the code to use the new column and deploy
- drop the old column